Desde el inicio de nuestra andadura en abril de 2022, el proyecto OLIVO 4.0, perteneciente al Proyecto Matriz GEN4OLIVE, ha evolucionado de acuerdo con los tiempos establecidos. Durante este tiempo se han tomado datos de crecimiento de distintas variedades de olivo clasificándolas, según el patrón de crecimiento de cada variedad, en 3 clases: Rápido, medio y lento.
La recopilación de dicha información tiene dos objetivos fundamentales: estudiar cómo ha evolucionado el crecimiento de las plantas y estimar su evolución a futuro. El interés para la metodología de trabajo de un vivero es enorme ya que permite informar al cliente de un calendario de entrega mucho más ajustado a la realidad (sujeto a las condiciones climáticas y biológicas del cultivo), optimizando la planificación y ejecución de los trabajos programados.
De esta forma, en función de la altura de la planta y de las necesidades de plantación del cliente, se establece un programa “ex-ante” que permite, entre otras cosas, planificar el corte de estaquillas, distribuir la plantación de los invernaderos de crecimiento, elaborar con mayor precisión el calendario de abonado y optimizar la aplicación de tratamientos fitosanitarios.
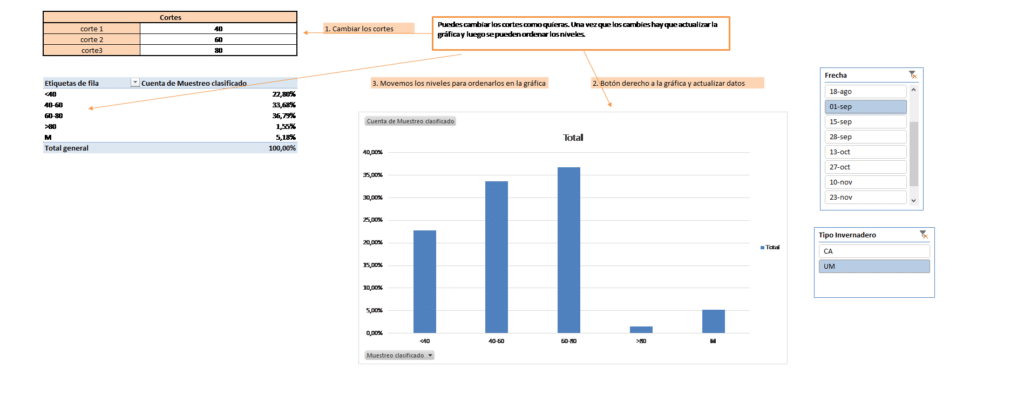
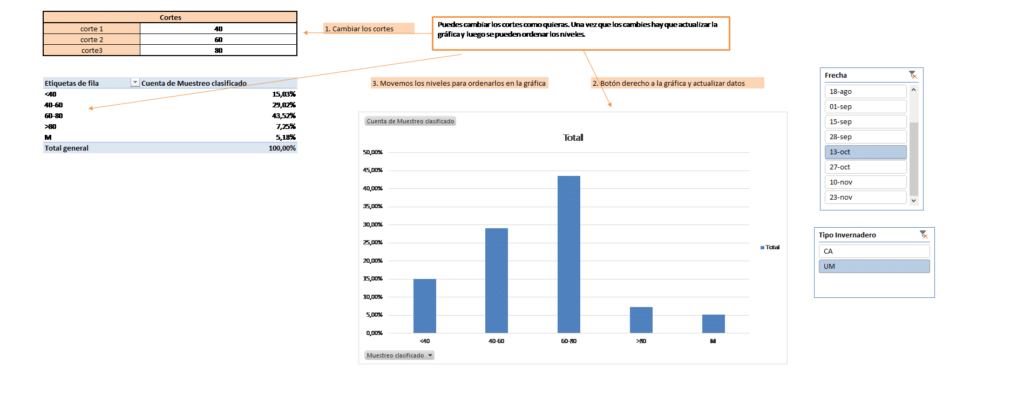
Para conseguir dichos objetivos, es fundamental realizar un buen muestreo en los invernaderos de forma que la muestra seleccionada sea representativa del comportamiento general (siempre bajo mismas variedades y características). Este diseño muestral se realiza mediante técnicas estadísticas y establece la distribución de plantas a muestrear por invernadero, variedad y enraizamiento. Para ello la acotación de error se ha establecido en el 10%. La unión de estos datos a otra información relevante susceptible de afectar al cultivo, como las características de los invernaderos, datos climáticos interiores y exteriores al invernadero, luminosidad, tipología de variedad, etc., permite obtener una base de datos amplia e integrada. Una vez tengamos todos los datos, se corrigen todas las anomalías presentes en los datos con distintas técnicas matemáticas y estadísticas. Por último, se crea una base de datos con toda esta información.
Una vez tenemos la información agrupada en una base de datos conjunta, se generan entradas para los modelos a través de distintas combinaciones espacio temporales calculadas matemáticamente que proporcionen la mayor información posible, con el objetivo de ayudar al correcto aprendizaje de los modelos. Estos modelos se basan en un conjunto amplio de modelos matemáticos de predicción (públicos y propios) basados en cada horizonte de predicción y patrón de crecimiento. Con el histórico de datos disponible, el ajuste de los modelos es del 95% para el horizonte de predicción más cercano y que se corresponde con la predicción a un mes vista.
Los resultados (evolución real y predicciones) se presentan de forma dinámica, de manera que es posible visualizar gráficamente la estimación del porcentaje de plantas según el tamaño discretizado en 4 niveles por variedad, fecha y tipología de invernadero.